良きコンテンツとの出会いはどのようにして生み出されるのでしょうか?
また、コンテンツは読者との出会いを経てどのように歩んでいくのでしょうか?
本稿では、読者が情報(コンテンツ)とどう出会い、そして、それをどう活用していくのかを考えます。
情報(コンテンツ)を提供するメディアビジネスにとり、そのプロセス再定義すべき時期にさしかかっています。
本稿では、筆者(藤村)が日ごろ実践している、情報の収集 — 整理 — 発信 — 保管のプロセスを紹介し、そこにまつわる問題意識の提示を試みるものです。
これは本ブログで論じた「読書体験の拡張は可能か?——いくつかの電子書籍/雑誌論をめぐる断片」および「読書体験を拡張する——ごく私的な試論として」の続編に当たるものです。
さて、どうしてこのような情報の処理プロセスを論じる必要があるのでしょうか?
ひとつには、私たちが好むと好まざるとにかかわらず、日々接している情報(コンテンツ)はますます膨大になっています。それを受け止め(あるいは、フィルターして)処理する仕組みやスキルは、個人に委ねられており、なんらかの支援が必要になっています。ここにビジネス機会を感じ取るからです。
もう一つには、筆者らが携わるデジタルメディア事業をめぐっても、情報(コンテンツ)をどう供給するかまでの議論はあっても、それが読者にとってどのように処理されるべきなのかに踏み込んだ議論が見当たりません。
これもまた、ビジネス機会と思わずにはいられないからです。
ビジネス機会をいかに生かすかについて、後ほど触れることにします。
さて、筆者の場合、多くの情報(コンテンツ)への設定はもちろん、デジタルによる入力が中心です。書籍や雑誌、あるいは自分人のメモなど、アナログな入力も含まれます。
筆者にとってのデジタルを主とする入力源は、以下のとおりです。
- Web ブラウザ……もちろん Web ブラウザの役割は、随時検索をしたりとなくなりません。Web ブラウザは依然として重要な情報(コンテンツ)の入力源です。筆者は Chrome を多用します。
- RSS リーダー……多くのメディアなど有用な情報源をカテゴリー別のなどに整理登録しておき、その最新情報を総覧できるツール。これひとつで多くの商業メディアや無数のブログなどをいちいち Web ブラウザで見て歩く必要がなくなります。feedly、Reeder などをお気に入りにしています。
- Twitter/Facebook……ソーシャルメディアは貴重な情報源です。信頼・尊敬する知人らがもたらすニュースや専門情報などには啓発されることが多く、適度な注意を払うようにしています。
- 書籍や雑誌、あるいは印刷配布物……説明の必要はないでしょう。個人的には書籍の読書がデジタルへと移行するにはまだまだ時間がかかるものと見ています。
上記に加えてメルマガなどを運んでくる電子メールも情報源と言えますが、ここでは省きます。
ところで、このように多くの入力源から得たひらめきや、知識、問題意識などをどう処理すべきでしょうか?
筆者のケースでは、ひらめきや自分の問題意識に刺さったものは、なるべくソーシャルメディア上の知人、同好の士へシェア(おすそ分け)するようにつとめています。
Twitter の「ツィート」、Facebook の「近況アップデート」などです。
このようなシェアは、情報の鮮度や品質(あやしげでないもの)を重視し出典やポイントになる箇所とともに伝達します。逆にあまり自分の意見などで料理しすぎないように意識しています。
もちろん、シェアで終わってしまうケースもありますが、実は問題意識に深く刺さったものはそれを整理保管し、そのいくつかは、ブログに仕立てたり企画書や提案書に生かすようにしているのです。
そうすると、情報(コンテンツ)処理のフローは、多種の入力源から始まり、一部はいくつかのソーシャルメディアへの出力へと向かい、さらには以後の活用を意識した保管庫(への出力)へと向かっていくこととなります。
これまでは、長く、このような入力 — 各種出力 — 整理保管に相当するプロセスを、個々に“便利”なソフトウェアや Web サービスを利用していたのですが、目にする情報量が増え続け、かつ、出力先が増えたりと、効率化抜きではやりきれなくなってきました。
情報(コンテンツ)処理をフロー化する
そこで、ここ1年は以下に説明するような“体系”に即して、情報(コンテンツ)処理を励行するようになりました。下図をご覧ください。
各種の入力源を通して“気になる情報”“これは使いたい資料”“知人らが喜びそうな耳より情報”などが飛び込んできます。
それをその場で熟読し、ソーシャルメディアへシェア、さらにはブログも書き始める……というのは現実的ではありません。
ニュースなど情報に接している時間=情報発信(表現活動)の時間とは言えないからです。
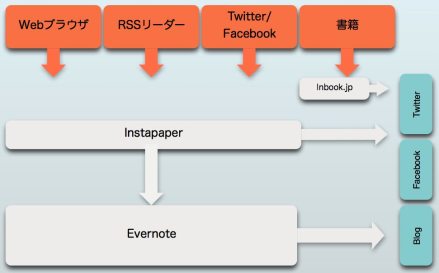
価値ある情報との出会いは、まず“後で読む”でクリップ
そこで、活用しているのが、“後で読む”系サービスの Instapaper です。同種のサービスやソフトは多種ありますが、筆者は Instapaper を気に入っています。
先ほど述べたような“これは!”という情報を、RSSリーダー、Webブラウザ、ソーシャルメディア上で見つけた場合、それを Instapaper へとクリッピング(簡略に記録しておく)します。多くのツール類が Instapaper へのクリッピング用ボタンを備えており、操作は1アクションですみます。
このように、入力から出力、保管へと進むプロセスの間に、“後で読む”系の層(レイヤー)を挟むようにしているのです。
※ 残念ながら、書物等にはこの便利な操作が適用できませんから、筆者の場合は遠慮なく印刷物に書き込みやマークなどを付します。そしてそれがまとまったところで、書籍や雑誌の記事内容を短く引用してソーシャルメディアに出力してくれるサービス Inbook.jp に投稿しています。これでソーシャルメディアへの出力と自分のための整理保管の両方の目的を果たします。
クリップした情報(コンテンツ)から“シェア”
Instapaper は後で丁寧に読み返したいというニーズに対応した記録用ツールですが、加えて重要な二つの機能を備えています。
ひとつは、リーダー(閲覧)機能。Web ブラウザと異なり、読者がニュースなどのコンテンツを読む際に不要な要素を取り払い記事を非常に読みやすいように整形表示してくれます。
もうひとつは、多様なシェア機能です。Facebook や Twitter、そして後で触れる Evernote など多種多様なクラウド系サービスと連携してくれます。
そこで、いったん溜め込んだ(クリップした)情報(コンテンツ)を、リーダー機能を使って読み返し、その中から重要と見定めた情報を選択し、今度は Instapaper のシェア機能からソーシャルメディアに向けて出力します。
このような機能を、Instapaper はデスクトップPCでも、スマートフォンでも、そしてタブレット、Amazon Kindle など多様な機器上で実現してくれることも重要なポイントなのです。
再利用に向け、整理保管へ
ソーシャルメディアへシェアして、フローを終了させてしまっては自分の中に残る問題意識は希薄なままです。
そこで、筆者の場合はさらにシェアした情報(コンテンツ)などを整理分類などして保管し、多少の熟成期間を経てブログへと再利用するようにしています。
ソーシャルメディアに向けて出力する情報は、15〜20本/日程度。一方、ブログは2本/週に過ぎません。
結果としては、多くの情報を再利用しないままとなってしまいます。
入力源の多くの情報(コンテンツ)> ソーシャルメディアへ出力する情報群 > 問題意識を論じたブログ
という数量的な不等号関係は避けられません。利用/非利用も含めて、情報の最後の整理保管庫に Evernote を活用しています。
Instapaper は比較的気軽なクリッピング手法で、基本はリンクを保管するものです。そこで、ソーシャルメディアへの出力後は、重要なものは Evernote へ整理保管しその他は Instapaper 上から削除してしまいます。言わば、仮保管庫で鮮度が高い間の処理にその利用用途を限定します。
Evernote はリンクではなくコンテンツ本体を複製保管するため、永続的な保管用途に耐えます。ノートの分類やタグづけなどを施し無制限に保存しておく使い方が適していると見ます。
ただし、人によっては Instapaper 層をすべて Evernote で置き換える利用方法も可能でしょう。Evernote には“後で読む”的機能はもちろん、Facebook と Twitter へとシェアする機能も備わっているからです。
さて、筆者の情報(コンテンツ)の処理プロセスをフロー化する手法を説明してきました。
こう整理してみて改めて課題と考えるのは、情報(コンテンツ)との出会いをかなり広めにとるのを余儀なくされていることです。
「メディアの『パーソナライズ』を改めて考える」で述べたように、情報(コンテンツ)との出会いを広げるだけではなく絞る手法もなければ、上述してきたフローは早晩行き詰まってしまうことでしょう。
ところで、このような多少凝ったフロー化を組み立てるようなアプローチが、これ以上多くの人に習慣化されるとは、実は筆者自身も考えていません。
最近、読んだ奥村倫弘著『ヤフー・トピックスの作り方』では、非常に多くの読者は私が上述したようなツールやサービスを自ら駆使してニュースと接触するような行動は好まないことを示しています。

奥村倫弘著『ヤフー・トピックスの作り方』(光文社サイトより)
ヤフー・ニュースの記事検索サービスは、自分が気になるキーワードを登録して、いつでも検索結果を見られるようにしておくことができました。この仕組みは、かれこれ10年間くらい続いたのですが、利用者がほとんどいないために機能提供を終了しました。
RSS リーダーの機能をヤフー・ニュースのトップページに設置したこともあります。……設定さえしてしまえば、ヤフー・ニュースが記事配信を受けていない朝日新聞や日本経済新聞の記事まで読めてしまうという、ちょっと画期的な仕組みだったのですが、こちらもまったく利用者が増加する見込みが立たずにサービスを終了しました。
どういうわけかヤフー・ニュースでは、読者自身がテーマを設定して自分の興味あるニュースを引き出すというセルフサービスは、うまく機能してこなかったのでした。
「ヤフー・ニュース」の経験で理解できることは、多くの読者はいくつものツールやサービスを自覚的に探求してまで、情報(コンテンツ)への接点を整備しようとは思わないということです。
言い換えれば、自覚的な手間を積み重ねることはおっくうでも、このようなフローが無意識に、自然に実現できることには需要があるとも思えます。
自らの情報(コンテンツ)接点は必ず記録(ログ)化されていて、思い出したときにそれをすぐさま取り出した上で活用できる——という仕掛けには隠された鉱脈があるとの仮説を持ちます。
従来、メディアビジネス(たとえば、出版社ら)は、このような情報処理プロセス全体にわたるような提案を読者に向けて行うことはありませんでした。
そこで、読者らは出版社からではなく、別のサービス提供者からこのような処理プロセスをフロー化していくソリューションを受け取ることになっているのではないか。
生み出された情報(コンテンツ)が生み出され、読者へと渡り、そしてそれがどのように消費、再利用されていくのか、コンテンツがたどる旅路の全体像を見通す構想が求められているのです。
(藤村)
