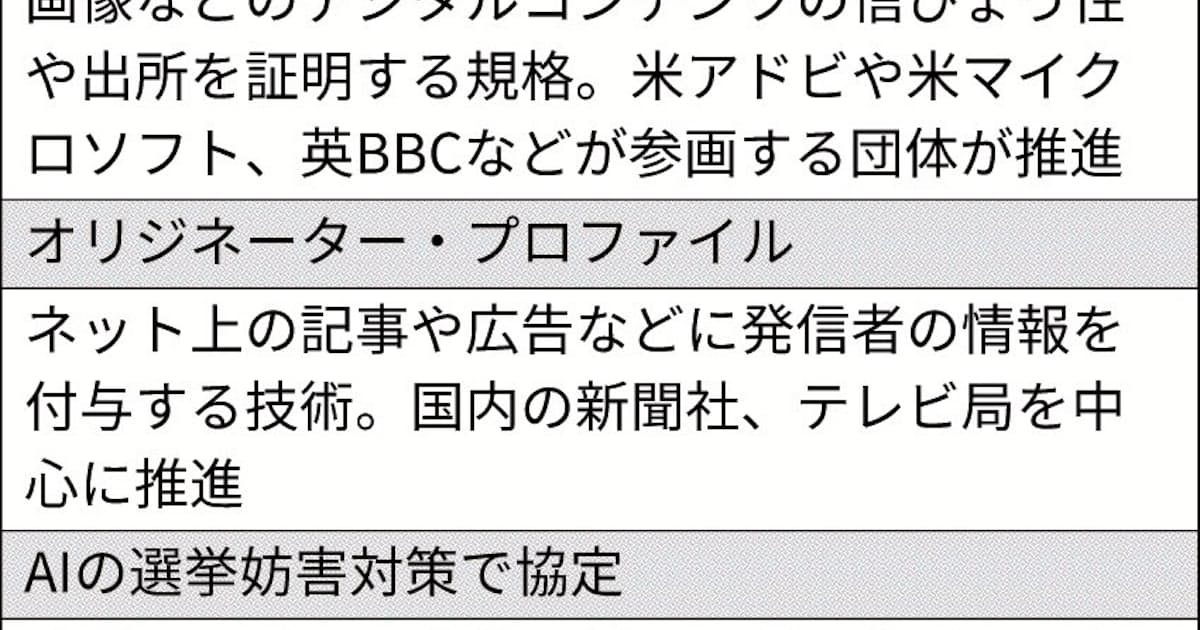
目に止まったメディアとテクノロジーに関する“トピックス”。2024年7月8日から2024年7月12日まで。
Local News Now | Elevating local news.
Local News Now | Elevating local news.

CNNが100人削減、年内に新たなオンラインチャンネル開設へ
Bloomberg.com

——CNNの新たなデジタル戦略とそのアウトプットであるインターネット番組が年内にもサービスインする。その準備の過程でレイオフも発表。その新生CNNを率いるCEOは、ご存じMark Thompson氏。前New York TimesのCEOだ。同氏のデジタル戦略も徐々に明らかになりつつある。別途紹介しよう。

NYTimesは、これを「無関係、不適切な嫌がらせ」と反論する。
アルファベットに埋もれた秘宝、ユーチューブには4550億ドルの価値
Bloomberg.com

——記事を読めば理解できるはずだが、米Alphabetは従来の検索事業主体であるGoogleをはじめとする多種の技術系事業のコングロマリット。YouTubeもその一つで、投資家らはYouTube単独価値に投資できない。検索事業などはAI進化の方向ひとつで価値毀損する恐れがある一方、YouTubeやそのエコシステムにはそのリスクがほぼない。この価値が隠されている事は問題だとする指摘を取り上げた記事だ。


Washington Post ‘third newsroom’ creation gets underway
Press Gazette

Google検索も不要に? 検索AI「Perplexity」がスゴすぎてちょっと怖い
ITmedia NEWS

最新情報をベースに、有力候補4人を抽出した上で、石丸伸二氏が猛追する展開を簡潔にまとめている」。
——「こんなふうに」の先は、記事内のスクリーンショットを確認のこと。確かに凄い。そして、重要なのはほぼリアルタイムですぐれた情勢認識(メディアをはじめとするさまざまな情報源をリアルタイムで分析ということか)を示している。記事は、Perplexityが他のAIチャットボットに比べて明らかな誤りが少ない(信頼のおける情報源を採用しているということか)とも指摘する。

——例年行われている博報堂DYメディアパートナーズのメディア環境研究所の2024年版の整理。引用箇所はけっこう切実な問題で、問いかける人、答える人で「新聞(を読む)」の定義が異なっている事態が拡大している。私自身は“新聞(の閲読)体験”を印刷版を超えたものとして再定義しないと、新聞社の存続が危ぶまれると考える。逆に、そのように新聞社(のなかの人々)が自ら再定義できれば、社会的ニーズはもちろん、産業としての未来は開けるものと考える。

——「グーグルのAI部門、ディープマインドと研究部門、ジグソーの研究グループ」による調査リポートから。平和博さんのブログ記事から。世論への影響工作に続く悪用目的が「収益化」だ。「51件、20.5%を占めた」という。





















![パブリッシャーの「 AI ライセンス契約」に対する賛否両論 Vol.2 | DIGIDAY[日本版]](https://digiday.jp/wp-content/uploads/2024/06/robot-newspaper-digiday_eye.gif)